______ __ __ ______ __ __ ______ ______ __ /\ ___\ /\ \/ / /\ __ \ /\ \ / / /\ __ \ /\__ _\ /\ \ \ \___ \ \ \ _'-. \ \ \/\ \ \ \ \/ / \ \ __ \ \/_/\ \/ \ \ \ \/\_____\ \ \_\ \_\ \ \_____\ \ \__/ \ \_\ \_\ \ \_\ \ \_\ \/_____/ \/_/\/_/ \/_____/ \/_/ \/_/\/_/ \/_/ \/_/
In its infancy, the internet was a digital wild west where anyone could stake their claim and create something new. This freedom led to a growth of decentralized, innovative, and diverse online communities. Your average joe could now use the family PC to spread his ideas to the rest of the world without going through corporate media or censoring governments.
However, as the internet grew, a small number of tech companies rose to dominate the digital landscape. These tech titans, Google, Amazon, Facebook, Apple, wield immense power and resources, and use that influence to shape the internet in ways that benefit their bottom line. This has led to surveillance capitalism, as these companies often sell your data to advertisers for a profit, as you sign away your rights by “Accepting the Terms of Service” just so you can see the latest TikTok trend.
It doesn’t have to be this way. It’s now easier than ever to create and host your own website, and fight back against the conglomerate of Big Tech companies trying to own the internet. Creating and hosting your own simple and meaningful content on the internet helps proliferate knowledge, information, and your own perspective on life, without compromising the privacy of others.
As a primer, let’s talk about what a website really is. I’m sure you know you can enter google.com in a web browser and that white search box pops up, but how does that happen?
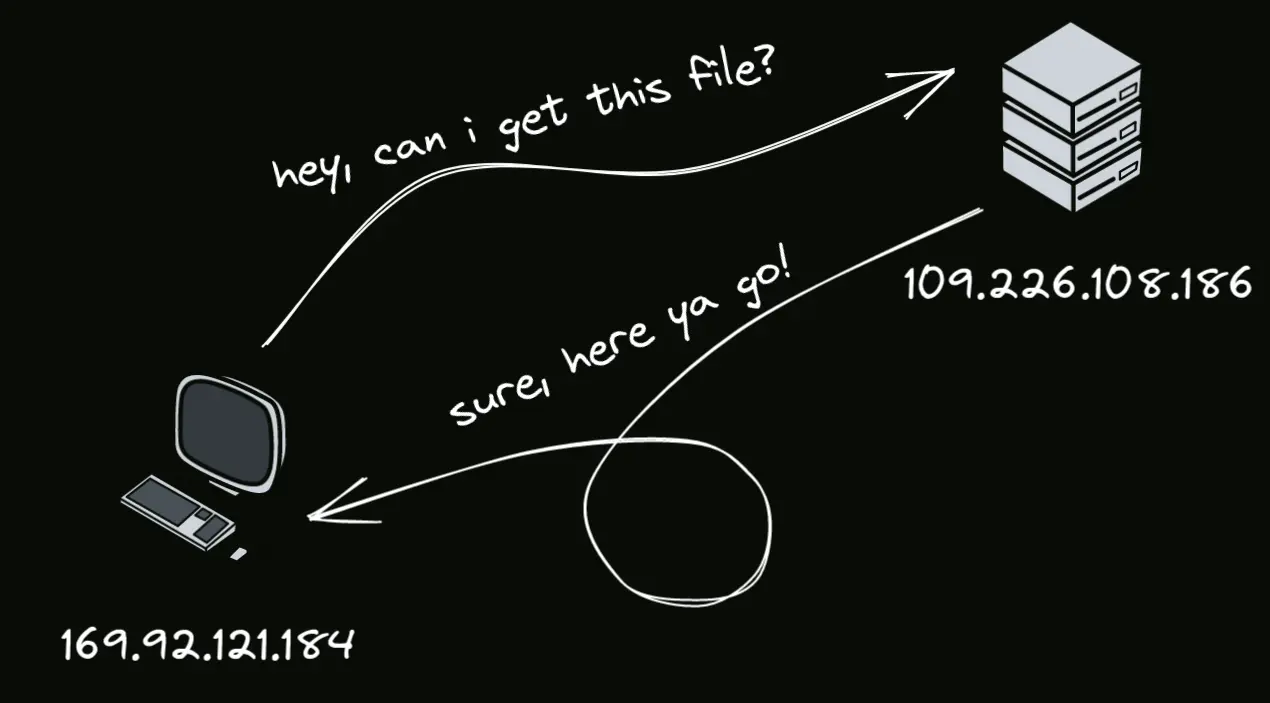
A website is just a connection of text files written using a fancy markup language that lets web developers represent the content of a website and how it should look. These files are then just stored on a server (which is just a computer connected to the internet), which listens for requests and responds with these files. Your web browser then receives these files and renders them to display the website like the developers intended.
In order to send and receive messages, every computer connected to the internet gets an IP address, a unique identifier. Snail mail works very similar to the internet protocol. In order to send a message, you place your package (data) in an envelope (IP packet), write the unique destination address (IP address) on it, and then let the postal service (internet service provider) route the mail for you. If you want a response, you can include your return address (your IP address) as well, so the recipient knows who to respond to.
As an aside, since humans aren’t good at memorizing arbitrary IP addresses, We maintain a system that stores mappings of domain names to IP addresses and translates them for us. Using a command line tool called drill, we can request the IP address that skovati.dev points to from cloudflare’s 1.1.1.1 DNS servers.
~ drill -Q @1.1.1.1 skovati.dev
173.195.146.139Which is the IP address of the server where this website is currently hosted, sourcehut!
Now that we know who to talk to, how do we actually get the website from them? HyperText Transfer Protocol, or HTTP for short, is a plain-text based protocol for asking for files from a web server. Once we know the IP address of the web server we want to talk to, we make a TCP connection, and then in plain text make a GET request for the index.html file that lives at the website root.
The web server that my domain name skovati.dev points to is listening for HTTP requests relating to skovati.dev, and will respond to requests with the HTML I’ve uploaded there.
Here I manually type out an HTTP request, after using openssl s_client to make a TCP connection with TLS.
HTTP GET Request
~ openssl s_client skovati.dev:443
GET / HTTP/1.1
Host: skovati.devAnd this is the HTTP Response we get back from the web server
HTTP/1.1 200 OK
Accept-Ranges: bytes
Content-Length: 4831
Content-Type: text/html; charset=utf-8
Last-Modified: Thu, 12 Jan 2023 17:02:43 GMT
Date: Wed, 18 Jan 2023 03:19:32 GMTAnd we recieve text-based HyperText Markup Language back
<!DOCTYPE html>
<html lang="en-us">
<head>
<meta charset="utf-8" />
<meta name="viewport" content="width=device-width,initial-scale=1" />
<title>hi, i'm skovati</title>
<link rel="icon" href="data:," />
<link rel="stylesheet" href="https://skovati.dev/style.min.css" />
</head>
<body>
<header>
=============
<br />==
<a href="https://skovati.dev/">skovati</a> ==
<br />=============
<div style="float:right">
a digital minimalist.
</div>
...Web browsers will then read this HTML response, request additional content defined in the index.html (CSS, images, etc), and then render the site!
This HTML file that gets returned actually entirely defines the homepage of my website. It is able to encode everything about my website into a compact text format that can easily be sent along slow connections, and your web browser reconstructs the web site using the following constructs that are part of HTML.
This represents the actual content of your site: text, links, photos, videos, audio, etc.
Here is HTML that represents a heading and paragraph:
<h1> This is a heading </h1>
<p> this is a paragraph with one <b> bold </b> word <p>And here is it actually rendered in your browser:
this is a paragraph with one bold word
CSS allows for styling and animation of content.
<style>
.test:hover {
color:red;
}
</style>
<span class="test"> test word </span>becomes: (hover over “test word”!)
test word
Javascript is a industry standard programming language that gets run client-side on your web browser. This allows extremely complex websites where users can dynamically interact with the web server and get bespoke HTTP responses.
<button type="button" onClick="update()">click me</button>
<p id="msg">no clicks yet!</p>
<script>
let counter = 0;
function update() {
counter += 1;
document.getElementById("msg")
.innerHTML = `clicked ${counter} time(s)`;
}
</script>no clicks yet!
WIP
last modified: (a683bf1)
the content for this site is CC-BY-NC-ND
the source code is MIT